Всем известно, что компьютеры могут выполнять вычисления с большими группами данных на огромной скорости. Но не все знают, что эти действия зависят всего от двух условий: есть или нет ток и какое напряжение.
Каким же образом компьютер умудряется обрабатывать такую разнообразную информацию?
Секрет заключается в двоичной системе исчисления. Все данные поступают в компьютер, представленные в виде единиц и нулей, каждому из которых соответствует одно состояние электропровода: единицам - высокое напряжение, нулям - низкое или же единицам - наличие напряжения, нулям - его отсутствие. Преобразование данных в нули и единицы называется двоичной конверсией, а окончательное их обозначение - двоичным кодом.
В десятичном обозначении, основанном на десятичной системе исчисления, которая используется в повседневной жизни, числовое значение представлено десятью цифрами от 0 до 9, и каждое место в числе имеет ценность в десять раз выше, чем место справа от него. Чтобы представить число больше девяти в десятичной системе исчисления, на его место ставится ноль, а на следующее, более ценное место слева - единица. Точно так же в двоичной системе, где используются только две цифры - 0 и 1, каждое место в два раза ценнее, чем место справа от него. Таким образом, в двоичном коде только ноль и единица могут быть изображены как одноместные числа, и любое число, больше единицы, требует уже два места. После ноля и единицы следующие три двоичных числа это 10 (читается один-ноль) и 11 (читается один-один) и 100 (читается один-ноль-ноль). 100 двоичной системы эквивалентно 4 десятичной. На верхней таблице справа показаны другие двоично-десятичные эквиваленты.
Любое число может быть выражено в двоичном коде, просто оно займет больше места, чем в десятичном обозначении. В двоичной системе можно записать и алфавит, если за каждой буквой закрепить определенное двоичное число.
Две цифры на четыре места
16 комбинаций можно составить, используя темные и светлые шары, комбинируя их в наборах из четырех штук Если темные шары принять за нули, а светлые за единицы, то и 16 наборов окажутся 16-единичным двоичным кодом, числовая ценность которого составляет от нуля до пяти (см. верхнюю таблицу на стр. 27). Даже с двумя видами шаров в двоичной системе можно построить бесконечное количество комбинаций, просто увеличивая число шариков в каждой группе - или число мест в числах.
Биты и байты
Самая маленькая единица в компьютерной обработке, бит - это единица данных, которая может обладать одним из двух возможных условий. К примеру, каждая из единиц и нулей (справа) означает 1 бит. Бит можно представить и другими способами: наличием или отсутствием электрического тока, дырочкой и ее отсутствием, направлением намагничивания вправо или влево. Восемь битов составляют байт. 256 возможных байтов могут представить 256 знаков и символов. Многие компьютеры обрабатывают байт данных одновременно.
Двоичная конверсия. Четырехцифровой двоичный код может представить десятичные числа от 0 до 15.
Кодовые таблицы
Когда двоичный код используется для обозначения букв алфавита или пунктуационных знаков, требуются кодовые таблицы, в которых указано, какой код какому символу соответствует. Составлено несколько таких кодов. Большинство ПК приспособлено под семицифровой код, называемый ASCII, или американский стандартный код для информационного обмена. На таблице справа показаны коды ASCII для английского алфавита. Другие коды предназначаются для тысяч символов и алфавитов других языков мира.

Часть таблицы кода ASCII
Давайте разберемся как же все таки переводить тексты в цифровой код ? Кстати, на нашем сайте вы можете перевести любой текст в десятичный, шестнадцатеричный, двоичный код воспользовавшись Калькулятором кодов онлайн .
Кодирование текста.
По теории ЭВМ любой текст состоит из отдельных символов. К этим символам относятся: буквы, цифры, строчные знаки препинания, специальные символы («»,№, (), и т.д.), к ним, так же, относятся пробелы между словами.
Необходимый багаж знаний. Множество символов, при помощи которых записываю текст, называется АЛФАВИТОМ.
Число взятых в алфавите символов, представляет его мощность.
Количество информации можно определить по формуле: N = 2b
- N - та самая мощность (множество символов),
- b - Бит (вес взятого символа).
Алфавит, в котором будет 256 может вместить в себя практически все нужные символы. Такие алфавиты называют ДОСТАТОЧНЫМИ.
Если взять алфавит мощностью 256, и иметь в виду что 256 = 28
- 8 бит всегда называют 1 байт:
- 1 байт = 8 бит.
Если перевести каждый символ в двоичный код, то этот код компьютерного текста будет занимать 1 байт.
Как текстовая информация может выглядеть в памяти компьютера?
Любой текст набирают на клавиатуре, на клавишах клавиатуры, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111.
Поскольку, байт - это самая маленькая адресуемая частица памяти, и память обращена к каждому символу отдельно - удобство такого кодирование очевидно. Однако, 256 символов - это очень удобное количество для любой символьной информации.
Естественно, встал вопрос: Какой конкретно восьми разрядный код принадлежит каждому символу? И как осуществить перевод текста в цифровой код?
Этот процесс условный, и мы вправе придумать различные способы для кодировки символов . Каждый символ алфавита имеет свой номер от 0 до 255. И каждому номеру присвоен код от 00000000 до 11111111.
Таблица для кодировки - это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для различных типов ЭВМ используют разные таблицы для кодировки.
ASCII(или Аски), стала международным стандартом для персональных компьютеров. Таблица имеет две части.
Первая половина для таблицы ASCII. (Именно первая половина, стала стандартом.)
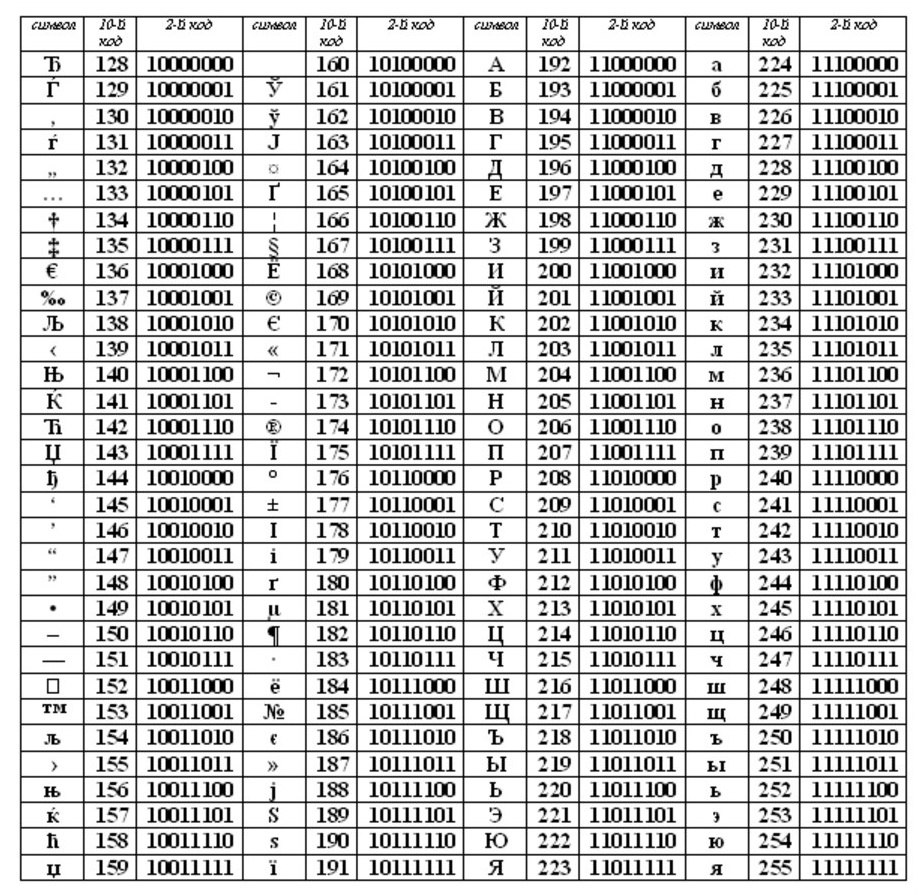
Соблюдение лексикографического порядка, то есть, в таблице буквы (Строчные и прописные) указаны в строгом алфавитном порядке, а цифры по возрастанию, называют принципом последовального кодирования алфавита.
Для русского алфавита тоже соблюдают принцип последовательного кодирования .
Сейчас, в наше время используют целых пять систем кодировок русского алфавита(КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за количества систем кодировок и отсутствия одного стандарта, очень часто возникают недоразумения с переносом русского текста в компьютерный его вид.
Одним из первых стандартов для кодирования русского алфавит а на персональных компьютерах считают КОИ8("Код обмена информацией, 8-битный"). Данная кодировка использовалась в середине семидесятых годов на серии компьютеров ЕС ЭВМ, а со средины восьмидесятых, её начинают использовать в первых переведенных на русский язык операционных системах UNIX.
С начала девяностых годов, так называемого, времени, когда господствовала операционная система MS DOS, появляется система кодирования CP866 ("CP" означает "Code Page", "кодовая страница").
Гигант компьютерных фирм APPLE, со своей инновационной системой, под упралением которой они и работали (Mac OS), начинают использовать собственную систему для кодирования алфавита МАС.
Международная организация стандартизации (International Standards Organization, ISO)назначает стандартом для русского языка еще одну систему для кодирования алфавита , которая называется ISO 8859-5.
А самая распространенная, в наши дни, система для кодирования алфавита, придумана в Microsoft Windows, и называется CP1251.
С второй половины девяностых годов, была решена проблема стандарта перевода текста в цифровой код для русского языка и не только, введением в стандарт системы, под названием Unicode. Она представлена шестнадцатиразрядной кодировкой, это означает, что на каждый символ отводится ровно по два байта оперативной памяти. Само собой, при такой кодировке, затраты памяти увеличены в два раза. Однако, такая кодовая система позволяет переводить в электронный код до 65536 символов.
Специфика стандартной системы Unicode, является включением в себя абсолютно любого алфавита, будь он существующим, вымершим, выдуманным. В конечном счете, абсолютно любой алфавит, в добавок к этом, система Unicode, включает в себя уйму математических, химических, музыкальных и общих символов.
Давайте с помощью таблицы ASCII посмотрим, как может выглядеть слово в памяти вашего компьютера.

Очень часто случается так, что ваш текст, который написан буквами из русского алфавита, не читается, это обусловлено различием систем кодирования алфавита на компьютерах. Это очень распространенная проблема, которая довольно часто обнаруживается.
Компьютер обрабатывает большое количество информации. Аудиофайлы, картинки, тексты - все это необходимо воспроизвести или вывести на экран. Почему двоичное кодирование является универсальным методом программирования информации любого технического оборудования?
Чем отличается кодирование от шифрования?
Зачастую люди отождествляют понятия "кодирование" и "шифрование", когда на самом деле они имеют разный смысл. Так, шифрованием называют процесс преобразования информации с целью ее сокрытия. Расшифровать зачастую может сам человек, который изменил текст, или специально обученные люди. Кодирование же применяется для обработки информации и упрощения работы с ней. Обычно используется общая таблица кодировки, знакомая всем. Она же встроена в компьютер.
Принцип двоичного кодирования
Двоичное кодирование основывается на использовании всего лишь двух символов - 0 и 1 - для обработки информации, используемой различными устройствами. Эти знаки назвали двоичными цифрами, на английском - binary digit, или bit. Каждый из символов занимает память компьютера в 1 бит. Почему двоичное кодирование является универсальным методом обработки информации? Дело в том, что компьютеру легче обрабатывать меньшее количество символов. От этого напрямую зависит и продуктивность работы ПК: чем меньше функциональных задач нужно выполнить устройству, тем выше скорость и качество работы.
Принцип двоичного кодирования встречается не только в программировании. С помощью чередования глухих и звонких ударов барабана жители Полинезии передавали информацию друг другу. Сходный принцип применяется и в где для передачи сообщения используются длинные и короткие звуки. «Телеграфная азбука» используется и сегодня.
Где используется двоичное кодирование?
Двоичное в компьютере используется повсеместно. Каждый файл, будь то музыка или текст, должен быть запрограммирован, чтобы в последующем он мог быть легко обработан и прочитан. Система двоичного кодирования полезна для работы с символами и числами, аудиофайлами, графикой.
Двоичное кодирование чисел
Сейчас в компьютерах числа представлены в закодированном виде, непонятном для обычного человека. Использование арабских цифр так, как мы себе представляем, для техники нерационально. Причиной тому является необходимость присваивать каждому числу свою неповторимый символ, что сделать порой невозможно.

Существуют две системы счисления: позиционная и непозиционная. Непозиционная система основана на использовании латинских букв и знакома нам в виде Такой способ записи достаточно сложен для понимания, поэтому от него отказались.
Позиционная система счисления используется и сегодня. Сюда входит двоичное, десятичное, восьмеричное и даже шестнадцатеричное кодирование информации.
Десятичной системой кодирования мы пользуемся в быту. Это привычные для нас которые понятны каждому человеку. Двоичное кодирование чисел отличается использованием только нуля и единицы.
Целые числа переводятся в двоичную систему кодирования путем деления их на 2. Полученные частные также поэтапно делятся на 2, пока не получится в итоге 0 или 1. Например, число 123 10 в двоичной системе может быть представлено в виде 1111011 2 . А число 20 10 будет выглядеть как 10100 2 .
Индексы 10 и 2 обозначаются, соответственно, десятичную и двоичную систему кодирования чисел. Символ двоичного кодирования используется для упрощения работы со значениями, представленными в разных системах счисления.
Методы программирования десятичных чисел основаны на “плавающей запятой”. Для того чтобы правильно перевести значение из десятичной в двоичную систему кодирования, используют формулу N = M х qp. М - это мантисса (выражение числа без какого-либо порядка), p - это порядок значения N, а q - основание системы кодирование (в нашем случае 2).
Не все числа являются положительными. Для того чтобы различить положительные и отрицательные числа, компьютер оставляет место в 1 бит для кодирования знака. Здесь ноль представляет знак плюс, а единица - минус.
Использование такой системы счисления упрощает для компьютера работу с числами. Вот почему двоичное кодирование является универсальным при вычислительных процессах.

Двоичное кодирование текстовой информации
Каждый символ алфавита кодируется своим набором нулей и единиц. Текст состоит из разных символов: букв (прописных и строчных), арифметических знаков и других различных значений. Кодирование текстовой информации требует использования 8 последовательных двоичных значений от 00000000 до 11111111. Таким образом можно преобразовать 256 различных символов.
Чтобы не было путаницы в кодировании текста, используются специальных таблицы значений для каждого символа. В них присутствует латинский алфавит, арифметические знаки и знаки особого назначения (например, €, ¥, и другие). Символы промежутка 128-255 кодируют национальный алфавит страны.
Для кодирования 1 символа требуется 8 бит памяти. Для упрощения подстчетов 8 бит приравниваются к 1 байту, поэтому общее место на диске для текстовой информации измеряется в байтах.

Большинство персональных компьютеров оснащены стандартной таблицей кодировки ASCII (American Standard Code for Information Interchange). Также используются другие таблицы, в которых система кодирования текстовой информации отличается. К примеру, первая известная кодировка символов называется КОИ-8 (код обмена информацией 8-битный), и работает она на компьютерах с ОС UNIX. Также широко встречается таблица кодов СР1251, которая была создана для операционной системы Windows.
Двоичное кодирование звуков
Еще одна причина, почему двоичное кодирование является универсальным методом программирования информации, - это его простота при работе с аудиофайлами. Любая музыка представляет собой звуковые волны разной амплитуды и частоты колебания. От этих параметров зависит громкость звука и его высота тона.
Чтобы запрограммировать звуковую волну, компьютер делит ее условно на несколько частей, или «выборок». Число таких выборок может быть большим, поэтому существует 65536 различных комбинаций нулей и единиц. Соответственно, современные компьютеры оснащены 16-битными звуковыми картами, что означает использование 16 двоичных цифр для кодирования одной выборки звуковой волны.
Чтобы воспроизвести аудиофайл, компьютер обрабатывает запрограммированные последовательности двоичного кода и соединяет их в одну непрерывную волну.
Кодирование графики
Графическая информация может быть представлена в виде рисунков, схем, картинок или слайдов в PowerPoint. Любая картинка состоит из мелких точек - пикселей, которые могут быть окрашены в разный цвет. Цвет каждого пикселя кодируется и сохраняется, и в итоге мы получаем полноценное изображение.
Если картинка черно-белая, код каждого пикселя может быть либо единицей, либо нулем. Если используется 4 цвета, то код каждого из них состоит из двух цифр: 00, 01, 10 или 11. По этому принципу различают качество обработки любого изображения. Увеличение или уменьшение яркости также влияет на количество используемых цветов. В лучшем случае компьютер различает около 16 777 216 оттенков.

Заключение
Существуют разные методы программирования информации, среди которых двоичное кодирование является наиболее эффективным. Всего лишь с помощью двух символов - 1 и 0 - компьютер легко прочитывает большинство файлов. При этом скорость обработки намного выше, нежели использовалась бы, например, десятичная система программирования. Простота этого метода делает его незаменимым для любой техники. Вот почему двоичное кодирование является универсальным среди своих аналогов.
Минимальные единицы измерения информации – это бит и байт.
Один бит позволяет закодировать 2 значения (0 или 1).
Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11.
Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111.
Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать:
1 бит кодирует –> 2 разных значения (2 1 = 2),
2 бита кодируют –> 4 разных значения (2 2 = 4),
3 бита кодируют –> 8 разных значений (2 3 = 8),
4 бита кодируют –> 16 разных значений (2 4 = 16),
5 бит кодируют –> 32 разных значения (2 5 = 32),
6 бит кодируют –> 64 разных значения (2 6 = 64),
7 бит кодируют –> 128 разных значения (2 7 = 128),
8 бит кодируют –> 256 разных значений (2 8 = 256),
9 бит кодируют –> 512 разных значений (2 9 = 512),
10 бит кодируют –> 1024 разных значений (2 10 = 1024).
Мы помним, что в одном байте не 9 и не 10 бит, а всего 8. Следовательно, с помощью одного байта можно закодировать 256 разных символов. Как Вы думаете, много это или мало? Давайте посмотрим на примере кодирования текстовой информации.
В русском языке 33 буквы и, значит, для их кодирования надо 33 байта. Компьютер различает большие (заглавные) и маленькие (строчные) буквы, только если они кодируются различными кодами. Значит, чтобы закодировать большие и маленькие буквы русского алфавита, потребуется 66 байт.
Для больших и маленьких букв английского алфавита потребуется ещё 52 байта. В итоге получается 66 + 52 = 118 байт. Сюда надо ещё добавить цифры (от 0 до 9), символ «пробел», все знаки препинания: точку, запятую, тире, восклицательный и вопросительный знаки, скобки: круглые, фигурные и квадратные, а также знаки математических операций: +, –, =, / (это деление), * (это умножение). Добавим также специальные символы: %, $, &, @, #, № и др. Все это вместе взятое как раз и составляет около 256 различных символов.
А дальше дело осталось за малым. Надо сделать так, чтобы все люди на Земле договорились между собой о том, какие именно коды (с 0 до 255, т.е. всего 256) присвоить символам. Допустим, все люди договорились, что код 33 означает восклицательный знак (!), а код 63 – вопросительный знак (?). И так же – для всех применяемых символов. Тогда это будет означать, что текст, набранный одним человеком на своем компьютере, всегда можно будет прочитать и распечатать другому человеку на другом компьютере.
Таблица ASCII
Такая всеобщая договоренность об одинаковом использовании чего-либо называется стандартом . В нашем случае стандарт должен представлять из себя таблицу, в которой зафиксировано соответствие кодов (с 0 до 255) и символов. Подобная таблица называется таблицей кодировки.
Но не всё так просто. Ведь символы, которые хороши, например, для Греции, не подойдут для Турции потому, что там используются другие буквы. Аналогично то, что хорошо для США, не подойдет для России, а то, что подойдет для России, не годится для Германии.
Поэтому приняли решение разделить таблицу кодов пополам.
Первые 128 кодов (с 0 до 127) должны быть стандартными и обязательными для всех стран и для всех компьютеров, это – международный стандарт.
А со второй половиной таблицы кодов (с 128 до 255) каждая страна может делать все, что угодно, и создавать в этой половине свой стандарт – национальный .
Первую (международную) половину таблицы кодов называют таблицей ASCII , которую создали в США и приняли во всем мире. За вторую половину кодовой таблицы стандарт ASCII не отвечает. Разные страны создают здесь свои национальные таблицы кодов. Может быть и так, что в пределах одной страны действуют разные стандарты, предназначенные для различных компьютерных систем, но только в пределах второй половины таблицы кодов.
Коды из международной таблицы ASCII
0-31 – особые символы, которые не распечатываются на экране или на принтере, а служат для выполнения специальных действий (например, для «перевода каретки» – перехода текста на новую строку, или для «табуляции» – установки курсора на специальные позиции в строке текста и т.п.).
32 – пробел (разделитель между словами – это тоже символ, подлежащий кодировке, хоть он и отображается в виде «пустого места» между словами и символами),
33-47 – специальные символы (круглые скобки и пр.) и знаки препинания (точка, запятая и пр.),
48-57 – цифры от 0 до 9,
58-64 – математические символы (плюс (+), минус (-), умножить (*), разделить (/) и пр.) и знаки препинания (двоеточие, точка с запятой и пр.),
65-90 – заглавные (прописные) английские буквы,
91-96 – специальные символы (квадратные скобки и пр.),
97-122 – маленькие (строчные) английские буквы,
123-127 – специальные символы (фигурные скобки и пр.).
За пределами таблицы ASCII, начиная с цифры 128 по 159, идут заглавные (прописные) русские буквы, а со 160 по 170 и с 224 по 239 – маленькие (строчные) русские буквы.
Кодировка слова МИР
Пользуясь показанной кодировкой, мы можем представить себе, как компьютер кодирует и затем воспроизводит, например, слово МИР (заглавными буквами). Это слово представляется тремя кодами: букве М соответствует код 140 (по национальной российской системе кодировки), И – это код 136 и Р – это 144.
Но как уже говорилось ранее, компьютер воспринимает информацию только в двоичном виде, т.е. в виде последовательности нулей и единиц. Каждый байт, соответствующий каждой букве слова МИР, содержит последовательность из восьми нулей и единиц. Используя правила перевода десятичной информации в двоичную, можно заменить десятичные значения кодов букв на их двоичные аналоги.
Десятичной цифре 140 соответствует двоичное число 10001100. Это можно проверить, если сделать следующие вычисления: 2 7 + 2 3 +2 2 = 140. Степень, в которую возводится каждая «двойка» – это номер позиции двоичного числа 10001100, в которой стоит «1», причем позиции нумеруются справа налево, начиная с нулевого номера позиции: 0, 1, 2 и т.д.
Более подробно о переводе чисел из одной системы счисления в другую можно узнать, например, из учебников по информатике или через Интернет.
Аналогичным образом можно убедиться, что цифре 136 соответствует двоичное число 10001000 (проверка: 2 7 + 2 3 = 136). А цифре 144 соответствует двоичное число 10010000 (проверка: 2 7 + 2 4 = 144).
Таким образом, в компьютере слово МИР будет храниться в виде следующей последовательности нулей и единиц (бит): 10001100 10001000 10010000.
Разумеется, что все показанные выше преобразования данных производятся с помощью компьютерных программ, и они не видны пользователям. Они лишь наблюдают результаты работы этих программ, как при вводе информации с помощью клавиатуры, так и при ее выводе на экран монитора или на принтер.
Следует отметить, что на уровне изучения компьютерной грамотности пользователям компьютеров не обязательно знать двоичную систему счисления. Достаточно иметь представление о десятичных кодах символов. Только системные программисты на практике используют двоичную, шестнадцатеричную, восьмеричную и иные системы счисления. Особенно это важно для них, когда компьютеры выводят сообщения об ошибках в программном обеспечении, в которых указываются ошибочные значения без преобразования в десятичную систему.
Упражнения по компьютерной грамотности , позволяющие самостоятельно увидеть и почувствовать описанные системы кодировок, приведены в статье
P.S. Статья закончилась, но можно еще прочитать:
P.P.S.
Чтобы подписаться на получение новых статей
, которых еще нет на блоге:
1) Введите Ваш e-mail адрес в эту форму.





